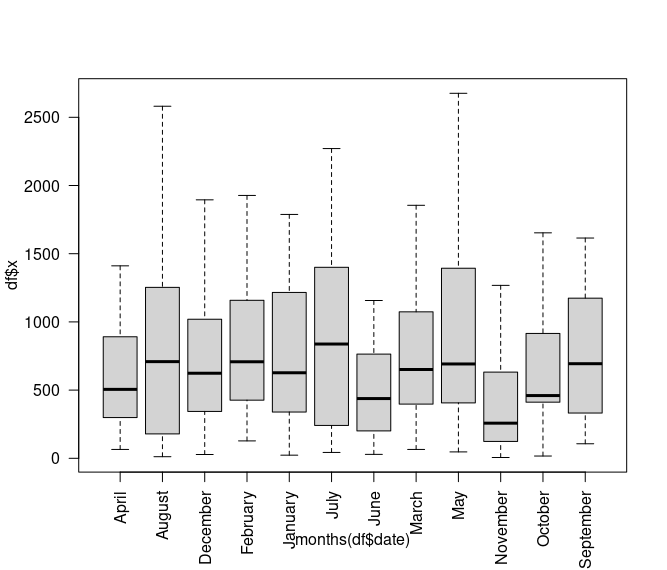
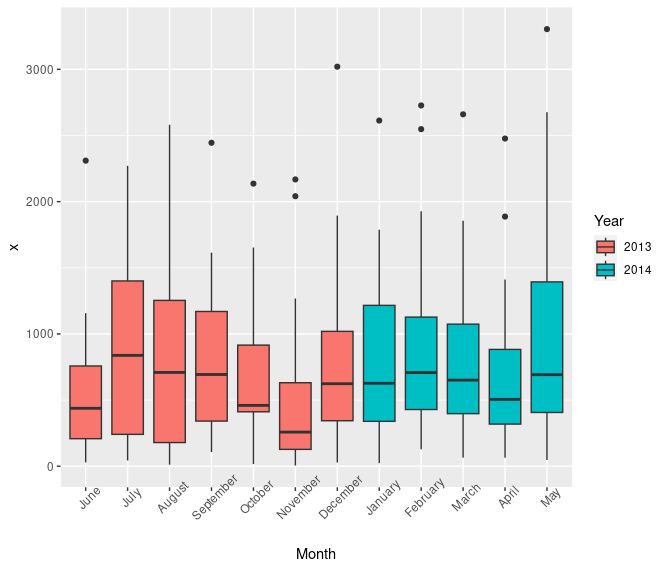
I have created demo code with Jupyter Notebook, which can be viewed here: https://github.com/marcuspaget/pythonDSFromScratch/blob/master/PandasDemo.md
Panda – Python Data Analysis Library
Quick install with:
pip install pandas
Python’s answer to R’s DataFrames for data manipulation
Providing tools to read and write data between data structures and different formats: CSV and text files, Microsoft Excel, SQL databases, and the fast HDF5 format;
Easily to manipulate, slice and dice data, with integrated indexing.
Possible to convert HDF5 to HDFS for ingestion in Hadoop
Time series-functionality:
- Date range generation & modification
- Frequency conversion
- Moving window statistics
- Join time series without losing data
Numpy – Python Number Library
pip install numpy
Create, manipulate , slice and run ops i.e std, mean, min, max, etc
Please see link at top for examples
Matplotlib – Python plotting and figures
pip install matplotlib
Graph data from lists, dataframes, etc.
For example:

I have created demo code with Jupyter Notebook, which can be viewed here: https://github.com/marcuspaget/pythonDSFromScratch/blob/master/PandasDemo.md